From rules to reasoning: the evolution of conversational AI (Part 2)

If you missed the first part, you can read it before continuing: From rules to reasoning: the evolution of conversational AI (Part 1)
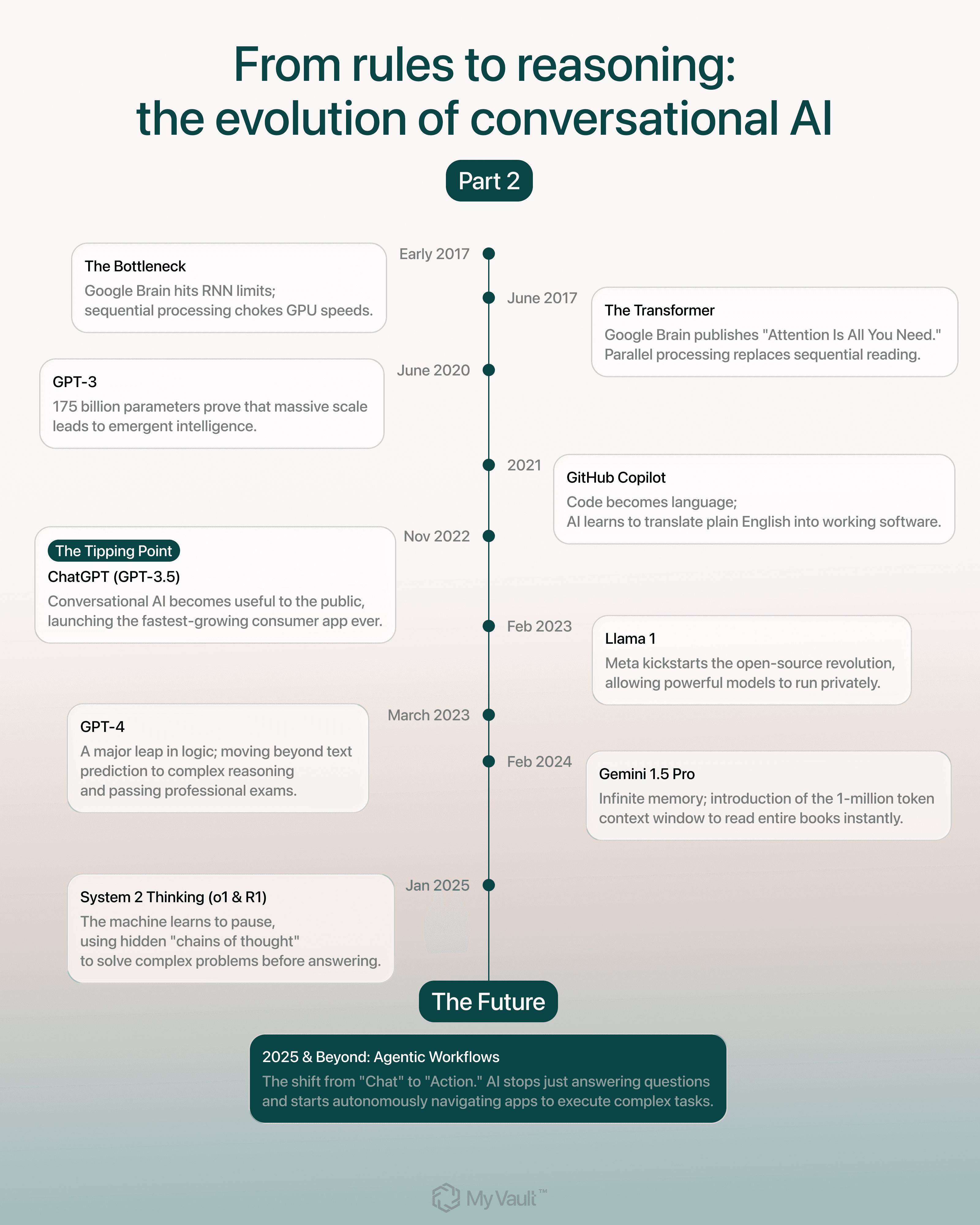
The revolution began with a bottleneck.
In early 2017, the researchers at Google Brain in Mountain View faced a physics problem disguised as a code problem. They had successfully moved from rule-based systems to neural networks, specifically Recurrent Neural Networks (RNNs). These models could translate text and generate sentences, yet they suffered from a fatal flaw.
They understood text one word at a time, like a person reading slowly.
To understand the end of a sentence, the RNN had to process every preceding word in order. Imagine trying to read a book, but you can only see one word at a time through a drinking straw. You lack the ability to glance ahead or look back. You must hold the entire meaning of the chapter in your memory as you crawl forward.
This sequential nature choked the hardware. Modern graphics chips (GPUs) excel at doing thousands of tiny math problems simultaneously. The RNN forced these powerful chips to wait in line. The hardware was ready for battle, but the software moved in slow, single-file traffic.
Infographic created by MyVault.
The parallel turn
In June 2017, Ashish Vaswani, Noam Shazeer, and six other authors published Attention Is All You Need, hypothesizing that strict ordering mattered less than connection. The paper introduced the "Transformer." This architecture abandoned the concept of time steps. It ingested an entire paragraph simultaneously.
They invented "self-attention" to replace the reading-in-order method.
Imagine you're at a crowded party. Dozens of people are talking at once, but someone nearby asks, “Do you want lemon in your drink?”
Your brain doesn’t process every word in sequence. It instantly links “lemon” and “drink,” understands they belong together, and interprets the meaning correctly even before you've got the entire sentence.
Transformers do the same thing with text. They detect the strongest relationships between words like “lemon” and “drink” regardless of the distance between them.
This architecture unlocked the true power of the GPU as Nvidia’s chips finally found a workload that matched their strength, causing training times to collapse and dataset sizes to explode.
The scaling hypothesis
OpenAI, (a small non-profit back then) in San Francisco, operated on a theory known as the "Scaling Hypothesis." The theory posited a crude relationship: if you increase the amount of data and the amount of compute, intelligence emerges as a byproduct.
Alec Radford, a researcher at OpenAI, tested this by feeding a Transformer seemingly endless amounts of text from the internet. He avoided teaching it grammar, logic, or facts. He simply played a game of "guess the next word."
He fed it the Common Crawl, a massive archive of the public web. The model read Wikipedia, Reddit threads, New York Times articles, and fan fiction.
The results shocked the field. As the model grew, it acquired skills it was never explicitly taught. It learned to translate French. It learned to write Python code. It learned to summarize articles.
These "emergent properties" appeared simply because the model had seen enough of the world’s information to understand its underlying structure. By predicting the next word, it learned the shape of human thought.
In 2020, OpenAI released GPT-3. It contained 175 billion parameters, the adjustable "synapses" in its digital brain. It demonstrated that quantity, effectively applied, becomes quality.
The codex
In 2021, OpenAI and GitHub launched Copilot. They trained the model on the entirety of public open-source code.Engineers realized that computer code is simply another language with its own grammar and syntax.
Suddenly, a developer could type a comment in plain English, like // function to calculate the monthly mortgage payment, and the ghost in the machine wrote the actual functioning code.
By 2024, models like Claude 3.5 Sonnet and GPT-4o had outgrown autocompletion. They were building code, logic, and structure like architects. A single user can now upload a screenshot of a whiteboard sketch, and the AI generates the functioning website, complete with styling and database logic.
The barrier to creation collapsed. The ability to write software had previously required years of study. Now, it requires only the ability to describe what you want.
The infinite memory
Early models suffered from amnesia and could remember only a few pages of text before the conversation drifted. If you fed them a book, they forgot the first chapter by the time they reached the third. In 2024, Google shattered this limitation with Gemini 1.5 Pro. They introduced a context window of one million tokens.
To visualize this, imagine a shelf of books. One million tokens is roughly 750,000 words, enough to hold the entire Harry Potter series in the model's working memory at the same time.
This transformed the way the tool could be used. A lawyer can upload thousands of pages of case discovery, including emails, contracts, and depositions, and ask the AI to find a specific contradiction. A financial analyst can feed in a company’s entire decade of earnings reports. The AI moves beyond a chat interface and becomes a research engine that reads the library instantly.
The pausing mind
Until 2024, Large Language Models operated on "System 1" thinking. Fast, instinctive, and prone to error. They answered immediately. If you gave them a riddle, they often blurted out the most obvious, incorrect answer.
In late 2024, OpenAI introduced the o1 series, with "System 2" thinking.Until then, Large Language Models operated on "System 1" thinking. Fast, instinctive, and prone to error. They answered immediately. If you gave them a riddle, they often blurted out the most obvious, incorrect answer.
When you ask o1 a complex math problem or a coding challenge, it pauses for ten, twenty, or thirty seconds while it thinks and generates a hidden chain of thought. During this time, it breaks the problem down into steps, tests a hypothesis, realizes when it made a mistake, and corrects itself. Only then does it deliver the answer.
This behavior mimics human deliberation. It allows the models to solve PhD-level physics problems and complex logic puzzles that baffled earlier versions. The machine learned the value of silence.
The Centaur
We are now in the first real decade of Centaur work. Chess grandmaster Garry Kasparov coined this term after losing to the computer Deep Blue and realizing that a human working with a machine could beat a machine working alone.
That’s what we’re witnessing now.
The Writer can use AI to generate ten variations of a headline and then rely on human judgment to pick the best one.
The Radiologist can have AI scan hundreds of X-rays and flag the 5% that look suspicious for a human to review.
The Programmer can act as an orchestrator, guiding a fleet of AI agents to handle boilerplate code while they focus on the system architecture.
The tool amplifies human capability and removes the drudgery of the blank page and the paralysis of the first draft.
The local future
This progression brings us back to the core tension of the digital age, the trade off between capability and privacy. The strongest models we use today including OpenAI's GPT-5 series, Anthropic's Claude 4 Opus, Google DeepMind's Gemini 3 Pro, Meta's Llama 4.x, and Alibaba's Qwen 3, all share one thing.
These models require fuel, and that fuel is your data. An AI agent can only book your flight if it knows your calendar, your credit card, and your passport details. It can only refactor your code if it reads your proprietary repository, and it can only summarize your health records if it reads your lab results.
The current centralized model demands that you send all of this data to a massive server farm in California, which creates a surveillance vulnerability and asks you to trust a corporation with the blueprint of your life.
This reality drives the mission of MyVault. Local Intelligence is here, and the hardware on our desks, from Apple Silicon chips to Nvidia RTX cards, now has the power to run these Transformers locally, bringing the model to the data.
MyVault lets the AI read your documents, index your life, and answer your questions without a single byte leaving your machine, decoupling intelligence from surveillance.
Moving beyond words toward spatially grounded intelligence
Local models fix the trust problem. The next leap fixes the understanding problem. Text models are impressive, but they still live in a flat world made of words. The real frontier is spatially grounded intelligence systems that understand geometry, physics, and cause and effect.
To get there, AI needs world models that combine language, vision, motion, and real physical constraints. Models that can look at a scene, track objects, predict what happens next, and plan actions instead of just describing them.
This shift unlocks everything from believable simulated worlds to AI that can design objects, navigate spaces, and collaborate with humans in a way that feels less like autocomplete and more like intelligence. And once models can reason about real dynamics, they can accelerate scientific discovery by simulating physical and biological systems with far more fidelity than today’s tools.
Related posts

Feb 3, 2026
Household systems that pay for themselves in hours
Mental load means remembering when car insurance renews, tracking which child needs new shoes, knowing the fridge filter expires next month. Every household runs on hundreds of small details that someone must hold in memory.

Sead Fadilpasic

Jan 27, 2026
The Habsburg effect: why your data just got more valuable
The European Habsburgs built an empire through strategic marriages, consolidating power by keeping bloodlines strictly within the family. Something similar is happening with AI right now.

Markos Symeonides

Jan 21, 2026
The superuser problem: why AI agents are 2026's “biggest insider threat”
The primary security issue with AI agents is their access.
Markos Symeonides
